Презентация субд презентация к уроку по информатике и икт (9 класс) на тему.
С помощью СУБД пользователь может:
- создавать структуру базы данных;
- заполнять базу данных информацией;
- редактировать (исправлять, дополнять) структуру и содержание базы данных;
- выполнять сортировку (упорядочивание) информации;
- осуществлять поиск информации в базе данных;
- выводить нужную информацию на экран монитора, в файл и на бумажный носитель;
- устанавливать защиту базы данных.
Именно наличие СУБД превращает огромный объём хранимых в компьютерной памяти сведений в мощную справочную систему, способную быстро производить поиск и отбор необходимой нам информации.
2.6.2. Интерфейс СУБД
Существуют СУБД, с помощью которых создаются крупные промышленные информационные системы. Для работы с этими системами нужны специальные знания, в том числе владение специализированными языками программирования.
Для ведения личных баз данных, а также баз данных небольших организаций используются более простые СУБД, работать с которыми могут обычные пользователи. Наиболее распространёнными СУБД такого типа являются Microsoft Access и OpenOffice.org Base. При запуске любой из них на экран выводится окно, имеющее строку заголовка, строку меню, панели инструментов, рабочую область и строку состояния (рис. 2.12).
Рис. 2.12.
Среда OpenOffice.org Base
Таблицы - это главный тип объектов. С ними вы уже знакомы. В таблицах хранятся данные. Реляционная база данных может состоять из множества взаимосвязанных таблиц.
Формы - это вспомогательные объекты. Они создаются для того, чтобы сделать более удобной работу пользователя при вводе, просмотре и редактировании данных в таблицах.
Запросы - это команды и результаты обращения пользователя к СУБД для поиска данных, сортировки, добавления, удаления и обновления записей.
Отчёты - это документы, сформированные на основе таблиц и запросов и предназначенные для вывода на печать.
2.6.3. Создание базы данных
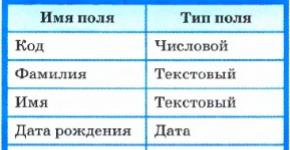
В качестве примера рассмотрим процесс создания базы данных «Наш класс». Она будет состоять из одной таблицы, имеющей следующую структуру:
-
СПИСОК (КОД, ФАМИЛИЯ, ИМЯ, ДАТА РОЖДЕНИЯ, ПОЛ, РОСТ, АДРЕС, УВЛЕЧЕНИЕ, НАЛИЧИЕ ПК).
Поля КОД и РОСТ будут числовыми; поле ДАТА РОЖДЕНИЯ будет иметь тип дата; поле НАЛИЧИЕ ПК будет логическим; все остальные поля будут иметь текстовый тип. Поле КОД можно считать ключом таблицы базы данных.

Создание базы данных начинается с открытия файла, в котором она будет храниться. Для этого нужно после запуска программы OpenOffice.org Base следовать указаниям мастера баз данных:
- создать новую базу данных;
- зарегистрировать базу данных (указать путь и имя файла).
Данные можно вводить непосредственно в таблицу (рис. 2.13), а можно создать для этого специальный шаблон - форму (рис. 2.14).
Рис. 2.13.
Таблица для ввода данных

Рис. 2.14.
Формы для ввода данных
После выполнения всех перечисленных выше действий будет получен следующий результат (рис. 2.15):

Рис. 2.15.
Таблица «Список» базы данных «Наш класс»
Созданная и сохранённая база данных в дальнейшем может быть открыта для добавления новых записей, исправления и удаления существующих, изменения содержимого отдельных полей и структуры всей таблицы.
Данные из таблиц можно упорядочить по некоторому признаку. Например, фамилии учеников в классном журнале записывают в алфавитном порядке; телепередачи в программе - в соответствии со временем их выхода в эфир; уроки в расписании - по возрастанию их порядковых номеров.
Упорядочение данных по возрастанию или убыванию значений некоторого признака называют сортировкой. Для выполнения сортировки указывают имя поля (имена полей), по которому будет произведена сортировка, и её порядок (возрастание или убывание значений поля).
2.6.4. Запросы на выборку данных
После того как база данных создана, её можно использовать в качестве справочной системы.
В командах СУБД условия выбора записываются в форме логических выражений - формализованных высказываний, сформулированных на естественном языке (табл. 2.6).
Таблица 2.6

В логических выражениях имена полей базы данных связываются с определёнными значениями этих полей операциями отношений:
не равно;
< меньше;
<= меньше или равно (не больше);
>= больше или равно (не меньше).
На уроках математики вы применяете эти операции, составляя и решая числовые равенства, неравенства и их системы.
Операции отношений применимы и к текстовым полям. Их сравнение построено на лексикографическом принципе: из двух слов меньшим считается то слово, первая буква которого идёт по алфавиту раньше; если первые несколько букв двух слов одинаковы, то сравнение производится по первой различающейся букве.
Значение поля текстового типа и некоторая текстовая величина равны, если они содержат одинаковое количество символов и все их символы, стоящие в позициях с одинаковыми номерами, совпадают.
При сравнении текстовых величин следует иметь в виду, что пробел - это тоже символ, хотя он и «меньше» любой буквы.
Сравнение дат построено иначе - одна дата считается меньше другой, если она относится к более раннему времени. Например, истинными будут следующие отношения:

Условия выбора могут задаваться не только простыми, но и сложными логическими выражениями, содержащими логические операции. С основными логическими операциями И, ИЛИ, НЕ вы познакомились в главе 1.
Таблица 2.7

С помощью запросов пользователь может быстро найти в базе данных и вывести на экран компьютера интересующую его информацию. Но для решения большинства практических задач найденную информацию необходимо представить в определённой форме и подготовить к выводу на печать. Этот этап работы называется подготовкой отчёта.
Самое главное
Программное обеспечение для создания баз данных, хранения и поиска в них необходимой информации называется системой управления базами данных (СУБД).
Основными объектами СУБД являются таблицы, формы, запросы, отчёты.
С помощью запросов на выборку данных, удовлетворяющих заданным условиям (условиям выбора), пользователь получает из базы данных только те записи и их поля, которые ему нужны. В командах СУБД условия выбора записываются в форме логических выражений.
Вопросы и задания

Свой вклад в исследование статистики русских фамилий внес и известный российский лингвист А. Ф. Журавлев – доктор филологических наук, заведующий отделом этимологии и ономастики Института русского языка им. В. В. Виноградова РАН (Москва).
А. Ф. Журавлевым к обсчету привлекались телефонные справочники нескольких городов России и других бывших советских территорий, библиотечные каталоги, оказавшиеся доступными персональные списки учреждений, списки абитуриентов некоторых московских вузов, разнообразные по характеру массивы ономастического (фамильного) материала в Интернете и пр. Однако обследованная им территория четко не очерчена, список городов, чьи телефонные справочники использовались, полностью не приведен (среди названных А. Ф. Журавлевым – Москва, Рязань, Владимир, Красноярск., на Украине – Большая Ялта). Принципы отбора городов недостаточно обоснованы. Дискуссионным является и сам характер добывания материала. Сам А. Ф. Журавлев признает, что не может «сколько-нибудь точно оценить общий объем ономастических единиц, попадавших в поле зрения, и, следовательно, долю в нем тех фамилий, которые вошли в итоговый список.
Из текущего в руки потока фамилий отбирались лишь те, которые попали в предварительный 800-единичный список (укороченный далее до 500 фамилий с наиболее надежной статистикой)». Сам же список из 800 единиц (т. е. фамилий) составлялся интуитивно. Все это снижает значимость полученных результатов, но тем не менее сам список из 500 наиболее частотных русских фамилий интересен. Число всех учтенных по разным источникам носителей первых 500 наиболее частых русских фамилий составляет несколько сотен тысяч. Очевидно, этот список еще будет уточняться, т. к. по заверению самого А. Ф. Журавлева, приведенная статистика «может быть признана имеющей лишь самый предварительный характер, но в любом случае лучшей, чем таблица Унбегауна» (имеется в виду приложение к книге «Русские фамилии» со списком самых частых фамилий Петербурга в 1910 г.).
Я решил привести эти 500 фамилий для ознакомления с ними посетителей сайта. Из материала А. Ф. Журавлева исключены две графы с данными для сравнения по статистике тех же фамилий в Петербурге в 1910 г. (они взяты из работы Б. О. Унбегауна). В итоговой таблице справа от фамилии приведено число, показывающее относительную встречаемость фамилии. Оно получено отнесением суммарной абсолютной частоты данной фамилии к суммарной абсолютной частоте наиболее распространенной у русских фамилии Иванов.
Итак, список, составленный А. Ф. Журавлевым. Во время подготовки к размещению на сайте обнаружилось, что в нем на три фамилии больше (они даны без порядкового номера). Для нахождения нужной фамилии воспользуйтесь функцией поиска Вашего браузера.
Ранг Фамилия Частотность 1 Иванов 1,0000 2 Смирнов 0,7412 3 Кузнецов 0,7011 4 Попов 0,5334 5 Васильев 0,4948 6 Петров 0,4885 7 Соколов 0,4666 8 Михайлов 0,3955 9 Новиков 0,3743 10 Федоров 0,3662 11 Морозов 0,3639 12 Волков 0,3636 13 Алексеев 0,3460 14 Лебедев 0,3431 15 Семенов 0,3345 16 Егоров 0,3229 17 Павлов 0,3226 18 Козлов 0,3139 19 Степанов 0,3016 20 Николаев 0,3005 21 Орлов 0,2976 22 Андреев 0,2972 23 Макаров 0,2924 24 Никитин 0,2812 25 Захаров 0,2755 26 Зайцев 0,2728 27 Соловьев 0,2712 28 Борисов 0,2710 29 Яковлев 0,2674 30 Григорьев 0,2541 31 Романов 0,2442 32 Воробьев 0,2371 33 Сергеев 0,2365 34 Кузьмин 0,2255 35 Фролов 0,2235 36 Александров 0,2234 37 Дмитриев 0,2171 38 Королев 0,2083 39 Гусев 0,2075 40 Киселев 0,2070 41 Ильин 0,2063 42 Максимов 0,2059 43 Поляков 0,2035 44 Сорокин 0,1998 45 Виноградов 0,1996 46 Ковалев 0,1978 47 Белов 0,1964 48 Медведев 0,1953 49 Антонов 0,1928 50 Тарасов 0,1896 51 Жуков 0,1894 52 Баранов 0,1883 53 Филиппов 0,1827 54 Комаров 0,1799 55 Давыдов 0,1767 56 Беляев 0,1750 57 Герасимов 0,1742 58 Богданов 0,1706 59 Осипов 0,1702 60 Сидоров 0,1695 61 Матвеев 0,1693 62 Титов 0,1646 63 Марков 0,1628 64 Миронов 0,1625 65 Крылов 0,1605 66 Куликов 0,1605 67 Карпов 0,1584 68 Власов 0,1579 69 Мельников 0,1567 70 Денисов 0,1544 71 Гаврилов 0,1540 72 Тихонов 0,1537 73 Казаков 0,1528 74 Афанасьев 0,1516 75 Данилов 0,1505 76 Савельев 0,1405 77 Тимофеев 0,1403 78 Фомин 0,1401 79 Чернов 0,1396 80 Абрамов 0,1390 81 Мартынов 0,1383 82 Ефимов 0,1377 83 Федотов 0,1377 84 Щербаков 0,1375 85 Назаров 0,1366 86 Калинин 0,1327 87 Исаев 0,1317 88 Чернышев 0,1267 89 Быков 0,1255 90 Маслов 0,1249 91 Родионов 0,1248 92 Коновалов 0,1245 93 Лазарев 0,1236 94 Воронин 0,1222 95 Климов 0,1213 96 Филатов 0,1208 97 Пономарев 0,1203 98 Голубев 0,1200 99 Кудрявцев 0,1186 100 Прохоров 0,1182 101 Наумов 0,1172 102 Потапов 0,1165 103 Журавлев 0,1160 104 Овчинников 0,1148 105 Трофимов 0,1148 106 Леонов 0,1142 107 Соболев 0,1135 108 Ермаков 0,1120 109 Колесников 0,1120 110 Гончаров 0,1115 111 Емельянов 0,1081 112 Никифоров 0,1055 113 Грачев 0,1049 114 Котов 0,1037 115 Гришин 0,1017 116 Ефремов 0,0995 117 Архипов 0,0993 118 Громов 0,0986 119 Кириллов 0,0982 120 Малышев 0,0978 121 Панов 0,0978 122 Моисеев 0,0975 123 Румянцев 0,0975 124 Акимов 0,0963 125 Кондратьев 0,0954 126 Бирюков 0,0950 127 Горбунов 0,0940 128 Анисимов 0,0925 129 Еремин 0,0916 130 Тихомиров 0,0907 131 Галкин 0,0884 132 Лукьянов 0,0876 133 Михеев 0,0872 134 Скворцов 0,0862 135 Юдин 0,0859 136 Белоусов 0,0856 137 Нестеров 0,0842 138 Симонов 0,0834 139 Прокофьев 0,0826 140 Харитонов 0,0819 141 Князев 0,0809 142 Цветков 0,0807 143 Левин 0,0806 144 Митрофанов 0,0796 145 Воронов 0,0792 146 Аксенов 0,0781 147 Софронов 0,0781 148 Мальцев 0,0777 149 Логинов 0,0774 150 Горшков 0,0771 151 Савин 0,0771 152 Краснов 0,0761 153 Майоров 0,0761 154 Демидов 0,0756 155 Елисеев 0,0754 156 Рыбаков 0,0754 157 Сафонов 0,0753 158 Плотников 0,0749 159 Демин 0,0745 160 Хохлов 0,0745 161 Фадеев 0,0740 162 Молчанов 0,0739 163 Игнатов 0,0738 164 Литвинов 0,0738 165 Ершов 0,0736 166 Ушаков 0,0736 167 Дементьев 0,0722 168 Рябов 0,0722 169 Мухин 0,0719 170 Калашников 0,0715 171 Леонтьев 0,0714 172 Лобанов 0,0714 173 Кузин 0,0712 174 Корнеев 0,0710 175 Евдокимов 0,0700 176 Бородин 0,0699 177 Платонов 0,0699 178 Некрасов 0,0697 179 Балашов 0,0694 180 Бобров 0,0692 181 Жданов 0,0692 182 Блинов 0,0687 183 Игнатьев 0,0683 184 Коротков 0,0678 185 Муравьев 0,0675 186 Крюков 0,0672 187 Беляков 0,0671 188 Богомолов 0,0671 189 Дроздов 0,0669 190 Лавров 0,0666 191 Зуев 0,0664 192 Петухов 0,0661 193 Ларин 0,0659 194 Никулин 0,0657 195 Серов 0,0657 196 Терентьев 0,0652 197 Зотов 0,0651 198 Устинов 0,0650 199 Фокин 0,0648 200 Самойлов 0,0647 201 Константинов 0,0645 202 Сахаров 0,0641 203 Шишкин 0,0640 204 Самсонов 0,0638 205 Черкасов 0,0637 206 Чистяков 0,0637 207 Носов 0,0630 208 Спиридонов 0,0627 209 Карасев 0,0618 210 Авдеев 0,0613 211 Воронцов 0,0612 212 Зверев 0,0606 213 Владимиров 0,0605 214 Селезнев 0,0598 215 Нечаев 0,0590 216 Кудряшов 0,0587 217 Седов 0,0580 218 Фирсов 0,0578 219 Андрианов 0,0577 220 Панин 0,0577 221 Головин 0,0571 222 Терехов 0,0569 223 Ульянов 0,0567 224 Шестаков 0,0566 225 Агеев 0,0564 226 Никонов 0,0564 227 Селиванов 0,0564 228 Баженов 0,0562 229 Гордеев 0,0562 230 Кожевников 0,0562 231 Пахомов 0,0560 232 Зимин 0,0557 233 Костин 0,0556 234 Широков 0,0553 235 Филимонов 0,0550 236 Ларионов 0,0549 237 Овсянников 0,0546 238 Сазонов 0,0545 239 Суворов 0,0545 240 Нефедов 0,0543 241 Корнилов 0,0541 242 Любимов 0,0541 243 Львов 0,0536 244 Горбачев 0,0535 245 Копылов 0,0534 246 Лукин 0,0531 247 Токарев 0,0527 248 Кулешов 0,0525 249 Шилов 0,0522 250 Большаков 0,0518 251 Панкратов 0,0518 252 Родин 0,0514 253 Шаповалов 0,0514 254 Покровский 0,0513 255 Бочаров 0,0507 256 Никольский 0,0507 257 Маркин 0,0506 258 Горелов 0,0500 259 Агафонов 0,0499 260 Березин 0,0499 261 Ермолаев 0,0495 262 Зубков 0,0495 263 Куприянов 0,0495 264 Трифонов 0,0495 265 Масленников 0,0488 266 Круглов 0,0486 267 Третьяков 0,0486 268 Колосов 0,0485 269 Рожков 0,0485 270 Артамонов 0,0482 271 Шмелев 0,0481 272 Лаптев 0,0478 273 Лапшин 0,0468 274 Федосеев 0,0467 275 Зиновьев 0,0465 276 Зорин 0,0465 277 Уткин 0,0464 278 Столяров 0,0461 279 Зубов 0,0458 280 Ткачев 0,0454 281 Дорофеев 0,0450 282 Антипов 0,0447 283 Завьялов 0,0447 284 Свиридов 0,0447 285 Золотарев 0,0446 286 Кулаков 0,0446 287 Мещеряков 0,0444 288 Макеев 0,0436 289 Дьяконов 0,0434 290 Гуляев 0,0433 291 Петровский 0,0432 292 Бондарев 0,0430 293 Поздняков 0,0430 294 Панфилов 0,0427 295 Кочетков 0,0426 296 Суханов 0,0425 297 Рыжов 0,0422 298 Старостин 0,0421 299 Калмыков 0,0418 300 Колесов 0,0416 301 Золотов 0,0415 302 Кравцов 0,0414 303 Субботин 0,0414 304 Шубин 0,0414 305 Щукин 0,0412 306 Лосев 0,0411 307 Винокуров 0,0409 308 Лапин 0,0409 309 Парфенов 0,0409 310 Исаков 0,0407 311 Голованов 0,0402 312 Коровин 0,0402 313 Розанов 0,0401 314 Артемов 0,0400 315 Козырев 0,0400 316 Русаков 0,0398 317 Алешин 0,0397 318 Крючков 0,0397 319 Булгаков 0,0395 320 Кошелев 0,0391 321 Сычев 0,0391 322 Синицын 0,0390 323 Черных 0,0383 324 Рогов 0,0381 325 Кононов 0,0379 326 Лаврентьев 0,0377 327 Евсеев 0,0376 328 Пименов 0,0376 329 Пантелеев 0,0374 330 Горячев 0,0373 331 Аникин 0,0372 332 Лопатин 0,0372 333 Рудаков 0,0372 334 Одинцов 0,0370 335 Серебряков 0,0370 336 Панков 0,0369 337 Дегтярев 0,0367 338 Орехов 0,0367 339 Царев 0,0363 340 Шувалов 0,0356 341 Кондрашов 0,0355 342 Горюнов 0,0353 343 Дубровин 0,0353 344 Голиков 0,0349 345 Курочкин 0,0348 346 Латышев 0,0348 347 Севастьянов 0,0348 348 Вавилов 0,0346 349 Ерофеев 0,0345 350 Сальников 0,0345 351 Клюев 0,0344 352 Носков 0,0339 353 Озеров 0,0339 354 Кольцов 0,0338 355 Комиссаров 0,0337 356 Меркулов 0,0337 357 Киреев 0,0335 358 Хомяков 0,0335 359 Булатов 0,0331 360 Ананьев 0,0329 361 Буров 0,0327 362 Шапошников 0,0327 363 Дружинин 0,0324 364 Островский 0,0324 365 Шевелев 0,0320 366 Долгов 0,0319 367 Суслов 0,0319 368 Шевцов 0,0317 369 Пастухов 0,0316 370 Рубцов 0,0313 371 Бычков 0,0312 372 Глебов 0,0312 373 Ильинский 0,0312 374 Успенский 0,0312 375 Дьяков 0,0310 376 Кочетов 0,0310 377 Вишневский 0,0307 378 Высоцкий 0,0305 379 Глухов 0,0305 380 Дубов 0,0305 381 Бессонов 0,0302 382 Ситников 0,0302 383 Астафьев 0,0300 384 Мешков 0,0300 385 Шаров 0,0300 386 Яшин 0,0299 387 Козловский 0,0298 388 Туманов 0,0298 389 Басов 0,0296 390 Корчагин 0,0295 391 Болдырев 0,0293 392 Олейников 0,0293 393 Чумаков 0,0293 394 Фомичев 0,0291 395 Губанов 0,0289 396 Дубинин 0,0289 397 Шульгин 0,0289 398 Касаткин 0,0285 399 Пирогов 0,0285 400 Семин 0,0285 401 Трошин 0,0284 402 Горохов 0,0282 403 Стариков 0,0282 404 Щеглов 0,0281 405 Фетисов 0,0279 406 Колпаков 0,0278 407 Чесноков 0,0278 408 Зыков 0,0277 409 Верещагин 0,0274 410 Минаев 0,0272 411 Руднев 0,0272 412 Троицкий 0,0272 413 Окулов 0,0271 414 Ширяев 0,0271 415 Малинин 0,0270 416 Черепанов 0,0270 417 Измайлов 0,0268 418 Алехин 0,0265 419 Зеленин 0,0265 420 Касьянов 0,0265 421 Пугачев 0,0265 422 Павловский 0,0264 423 Чижов 0,0264 424 Кондратов 0,0263 425 Воронков 0,0261 426 Капустин 0,0261 427 Сотников 0,0261 428 Демьянов 0,0260 429 Косарев 0,0257 430 Беликов 0,0254 431 Сухарев 0,0254 432 Белкин 0,0253 433 Беспалов 0,0253 434 Кулагин 0,0253 435 Савицкий 0,0253 436 Жаров 0,0253 437 Хромов 0,0251 438 Еремеев 0,0250 439 Карташов 0,0250 440 Астахов 0,0246 441 Русанов 0,0246 442 Сухов 0,0246 443 Вешняков 0,0244 444 Волошин 0,0244 445 Козин 0,0244 446 Худяков 0,0244 447 Жилин 0,0242 448 Малахов 0,0239 449 Сизов 0,0237 450 Ежов 0,0235 451 Толкачев 0,0235 452 Анохин 0,0232 453 Вдовин 0,0232 454 Бабушкин 0,0231 455 Усов 0,0231 456 Лыков 0,0229 457 Горлов 0,0228 458 Коршунов 0,0228 459 Маркелов 0,0226 460 Постников 0,0225 461 Черный 0,0225 462 Дорохов 0,0224 463 Свешников 0,0224 464 Гущин 0,0222 465 Калугин 0,0222 466 Блохин 0,0221 467 Сурков 0,0221 468 Кочергин 0,0219 469 Греков 0,0217 470 Казанцев 0,0217 471 Швецов 0,0217 472 Ермилов 0,0215 473 Парамонов 0,0215 474 Агапов 0,0214 475 Минин 0,0214 476 Корнев 0,0212 477 Черняев 0,0212 478 Гуров 0,0210 479 Ермолов 0,0210 480 Сомов 0,0210 481 Добрынин 0,0208 482 Барсуков 0,0205 483 Глушков 0,0203 484 Чеботарев 0,0203 485 Москвин 0,0201 486 Уваров 0,0201 487 Безруков 0,0200 488 Муратов 0,0200 489 Раков 0,0198 490 Снегирев 0,0198 491 Гладков 0,0197 492 Злобин 0,0197 493 Моргунов 0,0197 494 Поликарпов 0,0197 495 Рябинин 0,0197 496 Судаков 0,0196 497 Кукушкин 0,0193 498 Калачев 0,0191 499 Грибов 0,0190 500 Елизаров 0,0190 Звягинцев 0,0190 Корольков 0,0190 Федосов 0,0190

1. Создать структуру таблицы базы данных «Ученик» , содержащую следующие поля: фамилия, имя, школа, класс, дата рождения, вес . Типы и форматы полей определить самостоятельно.
2. Определить первичный ключ таблицы.
3. В режиме таблицы ввести в базу данных пять любых записей.
4. Добавить в структуру таблицы после поля «дата рождения» поле «рост» .
5. Заполнить поле «рост» .
6. С помощью мастера форм создать форму для редактирования таблицы.
7. В режиме формы ввести в таблицу пять любых записей.
8. Удалить из структуры таблицы поле «вес».
9. Удалить из таблицы вторую и пятую записи.

- Проверка домашней работы
- Введение нового материала
- Гипотетическая БД Действия с таблицами Команды выборки Создание и заполнение БД
- Гипотетическая БД
- Действия с таблицами
- Команды выборки
- Создание и заполнение БД
- Домашнее задание













- Выбрать где Выбрать всё
- Выбрать где
- Выбрать всё

База данных «Наш класс»
СПИСОК (КОД, ФАМИЛИЯ, ИМЯ, ДАТА РОЖДЕНИЯ, ПОЛ, РОСТ, АДРЕС, УВЛЕЧЕНИЕ, НАЛИЧИЕ ПК)
Поле КОД - ключ таблицы базы данных.
Имя поля
Тип поля
Числовой
Текстовый
Текстовый
Дата рождения
Текстовый
Числовой
Текстовый
Увлечение
Текстовый
Наличие ПК
Логический


Создание базы данных
Создание БД
Создать новую БД
Указать путь и имя файла
Зарегистрировать БД
Указать имена и типы полей
Описать структуру таблицы
Ввод в таблицу
Ввести данные
Ввод в форму

Таблица и формы для ввода данных
Таблица для ввода данных
Формы для ввода данных

Таблица «Список» БД «Наш класс»
Таблицу можно дополнять, редактировать.
Данные можно сортировать по нужному признаку.
 Меньше больше = меньше или равно больше или равно " width="640"
Меньше больше = меньше или равно больше или равно " width="640"
Запросы на выборку данных
Запрос или справка - таблица, содержащая интересующие пользователя сведения, извлечённые из базы данных.
Условия выбора записываются в форме логических выражений, в которых имена полей и их значения связаны операциями отношений.
Знак
Обозначение
меньше или равно
больше или равно
 # 31.12.95 # УВЛЕЧЕНИЕ ’ танцы ’ Номер записи Номер записи УВЛЕЧЕНИЕ = ‘ футбол ’ Номер записи Номер записи Номер записи ФАМИЛИЯ = ‘ Патрина ’ 1 Значение 6 8 Значение Значение Значение 1 Значение 2 10 2 4 1 1 Истина Истина Истина Истина Истина Истина Ложь Ложь Ложь Ложь Ложь Ложь " width="640"
# 31.12.95 # УВЛЕЧЕНИЕ ’ танцы ’ Номер записи Номер записи УВЛЕЧЕНИЕ = ‘ футбол ’ Номер записи Номер записи Номер записи ФАМИЛИЯ = ‘ Патрина ’ 1 Значение 6 8 Значение Значение Значение 1 Значение 2 10 2 4 1 1 Истина Истина Истина Истина Истина Истина Ложь Ложь Ложь Ложь Ложь Ложь " width="640"
Условия выбора
Высказывание
Ученик имеет персональный компьютер
Логическое выражение
Номер записи
Значение
Высказывание
Высказывание
Высказывание
Высказывание
Высказывание
Ученик не увлекается танцами
Логическое выражение
Ученик родился в 1996 году
Логическое выражение
Рост ученика не превышает 160 см
Логическое выражение
Ученик увлекается футболом
Логическое выражение
Логическое выражение
Фамилия ученика – Патрина
ДАТА # 31.12.95 #
УВЛЕЧЕНИЕ ’ танцы ’
Номер записи
Номер записи
УВЛЕЧЕНИЕ = ‘ футбол ’
Номер записи
Номер записи
Номер записи
ФАМИЛИЯ = ‘ Патрина ’
Значение
Значение
Значение
Значение
Значение
Истина
Истина
Истина
Истина
Истина
Истина
Ложь
Ложь
Ложь
Ложь
Ложь
Ложь
 31.03.98 29.11.95 0 9.11.95 06.12.99 14.06.98 05.09.99 Истина Ложь Истина Истина Ложь Ложь " width="640"
31.03.98 29.11.95 0 9.11.95 06.12.99 14.06.98 05.09.99 Истина Ложь Истина Истина Ложь Ложь " width="640"
Условия выбора даты
При сравнении дат одна дата считается меньше другой, если она относится к более раннему времени.
Высказывание
Значение
12.01.97 31.03.98
14.06.98 05.09.99
Истина
Ложь
Истина
Истина
Ложь
Ложь
 160 ИЛИ УВЛЕЧЕНИЕ = ` плавание ` Номер записи РОСТ 160 И УВЛЕЧЕНИЕ = ‘ плавание ’ 4 Значение Значение 4 Значение 10 7 1 10 Истина Истина Истина Ложь Ложь Ложь " width="640"
160 ИЛИ УВЛЕЧЕНИЕ = ` плавание ` Номер записи РОСТ 160 И УВЛЕЧЕНИЕ = ‘ плавание ’ 4 Значение Значение 4 Значение 10 7 1 10 Истина Истина Истина Ложь Ложь Ложь " width="640"
Сложные условия выбора
Высказывание
Высказывание
Высказывание
День рождения Ольги не 09.05.96
Логическое выражение
Логическое выражение
Логическое выражение
Рост ученика больше 160 см или ученик увлекается плаванием
Рост ученика больше 160 см, и ученик увлекается плаванием
Номер записи
Номер записи
ИМЯ = ` Ольга ` И ДАТА # 09.05.96 #
РОСТ 160 ИЛИ УВЛЕЧЕНИЕ = ` плавание `
Номер записи
РОСТ 160 И УВЛЕЧЕНИЕ = ‘ плавание ’
Значение
Значение
Значение
Истина
Истина
Истина
Ложь
Ложь
Ложь
3 И ИНФОРМАТИКА4 И ПОЛ= ` М ` (АЛГЕБРА4 ИЛИ ИНФОРМАТИКА4) И ПОЛ= ` Ж ` ФИЗИКА=3 ИЛИ АЛГЕБРА=3 ИЛИ ГЕОМЕТРИЯ=3 ИЛИ ИНФОРМАТИКА=3 (ФИЗИКА=3 ИЛИ АЛГЕБРА=3) И (ГЕОМЕТРИЯ=3 ИЛИ ИНФОРМАТИКА=3) ПОЛ= ‘ М ’ И СУММА55 ЗАДАЧА1=30 ИЛИ ЗАДАЧА2=30 ИЛИ ЗАДАЧА3=30 (ЗАДАЧА1ЗАДАЧА1=30 И ЗАДАЧА2=30 И ЗАДАЧА3=30 " width="640"
Вопросы и задания
В табличной форме представлены характеристики ноутбуков, имеющихся в продаже в компьютерном салоне:
В табличной форме представлен фрагмент базы данных с результатами олимпиады по информатике:
В табличной форме представлен фрагмент базы данных с годовыми оценками учащихся:
Фамилия
Алексеев
Алгебра
Геометрия
Информатика
Физика
Название
Жёсткий диск (ГБ)
Оперативная память (МБ)
Фамилия
Задача 1
Кузнецов
Задача 2
Михайлова
Задача 3
Сумма
Старовойтова
Какая СУБД установлена на компьютерах в вашем классе?
Что такое СУБД?
С чего начинается создание БД?
Перечислите основные объекты СУБД.
Какие функции они выполняют?
Какова цель запроса на выборку?
Какую строку будет занимать запись, содержащая сведения о ноутбуке Asus F70SL, после сортировки сначала по убыванию значений поля ОПЕРАТИВНАЯ ПАМЯТЬ, затем по возрастанию значений поля ЖЁСТКИЙ ДИСК?
Какую строку будет занимать запись, содержащая сведения о ноутбуке Asus F70SL, после сортировки по убыванию значений поля ЖЁСТКИЙ ДИСК?
Какую строку будет занимать запись, содержащая сведения о ноутбуке Asus F70SL, после сортировки по возрастанию значений поля НАЗВАНИЕ?
Сколько записей в данном фрагменте удовлетворяет следующему условию?
АЛГЕБРА3 И ИНФОРМАТИКА4 И ПОЛ= ` М `
(АЛГЕБРА4 ИЛИ ИНФОРМАТИКА4) И ПОЛ= ` Ж `
ФИЗИКА=3 ИЛИ АЛГЕБРА=3 ИЛИ ГЕОМЕТРИЯ=3 ИЛИ
ИНФОРМАТИКА=3
(ФИЗИКА=3 ИЛИ АЛГЕБРА=3) И (ГЕОМЕТРИЯ=3 ИЛИ
ИНФОРМАТИКА=3)
ПОЛ= ‘ М ’ И СУММА55
ЗАДАЧА1=30 ИЛИ ЗАДАЧА2=30 ИЛИ ЗАДАЧА3=30
ЗАДАЧА1=30 И ЗАДАЧА2=30 И ЗАДАЧА3=30

Как будет выглядеть список (фамилия, имя) учеников
после сортировки по возрастанию значений поля
ДАТА РОЖДЕНИЯ базы данных «Наш класс» ?
 #31.12.95# УВЛЕЧЕНИЕ= ` футбол ` ФАМИЛИЯ= ` Патрина ` УВЛЕЧЕНИЕ= ` танцы ` НАЛИЧИЕ ПК=1 " width="640"
#31.12.95# УВЛЕЧЕНИЕ= ` футбол ` ФАМИЛИЯ= ` Патрина ` УВЛЕЧЕНИЕ= ` танцы ` НАЛИЧИЕ ПК=1 " width="640"
которых будет истинным простое логическое выражение
ДАТА #31.12.95#
УВЛЕЧЕНИЕ= ` футбол `
ФАМИЛИЯ= ` Патрина `
УВЛЕЧЕНИЕ= ` танцы `
НАЛИЧИЕ ПК=1
 160 И УВЛЕЧЕНИЕ= ` плавание ` РОСТ 160 ИЛИ УВЛЕЧЕНИЕ= ` плавание ` ИМЯ= ` Ольга ` И ДАТА #09.05.96# " width="640"
160 И УВЛЕЧЕНИЕ= ` плавание ` РОСТ 160 ИЛИ УВЛЕЧЕНИЕ= ` плавание ` ИМЯ= ` Ольга ` И ДАТА #09.05.96# " width="640"
Укажите все записи базы данных «Наш класс», для
которых будет истинным сложное логическое выражение
РОСТ 160 И УВЛЕЧЕНИЕ= ` плавание `
РОСТ 160 ИЛИ УВЛЕЧЕНИЕ= ` плавание `
ИМЯ= ` Ольга ` И ДАТА #09.05.96#


Пространство рассуждения статьи затрагивает вопросы различия имен людей во всем мире, и то, как это влияет на дизайн форм ввода, баз данных, онтологий информатики и др. в контексте Всемирной Паутины.
Заинтересованная аудитория: авторы HTML-контента, разработчики скриптов серверных приложений (PHP, JSP и т.д.), менеджеры веб-проектов и любые другие люди, так или иначе связанные с дизайном форм ввода данных, дизайна баз данных и онтологий, которые затрагивают личные имена людей.
Следует помнить о различиях формирования и традициях употребления имен людей в других странах. Зачастую создатели сайтов или программ одной культуры не учитывают национальные особенности пользователя другой, что заставляет последнего чувствовать себя непривычно, и ставит дополнительные преграды к использованию продукта.
В данной статье не рассматриваются абсолютно все случаи. Связано это как с тем, что существует слишком много различных культур имени, все из которых невозможно описать и учесть сразу, так и с частой допустимостью неидеальных решений, соотвествующих лишь культурам большинства пользователей, что значительно экономит трудовые ресурсы. Здесь мы попытаемся лишь заострить внимание на основных примерах, показывающих решения в дизайне форм ввода и построении баз данных. Некоторые пункты иногда бывает необходимо учесть и в построении онтологий, хотя особых примеров здесь представлено не будет.
Случаи
Существует два основных случая, которые нужно предусмотреть.
- Вы выполняете дизайн формы в единственном языке (допустим, английском), которым будут пользоваться люди со всего мира.
- Вы выполняете дизайн формы в одном языке, но со временем данный элемент будет адаптирован под различные культурные особенности сферы языка конечного пользователя.
В реальной жизни вам наверняка не удастся выполнить локализацию для каждой культуры, поэтому даже если и вы полагаетесь на второй вариант, некоторым людям придется использовать форму, которая не была предназначена для их культурных особенностей.
Описания различий
Рассмотрим примеры того, как имена людей могут различаться в мире.
Имя и фамилия
В именовании «Бьорк Гвюдмюндсдоуттир» (Björk Guðmundsdóttir) собственно именем является Бьорк. Второе слово - отчество, составленное из имени отца (иногда - матери, но матронимы редки) и на конце -son (исл. сын) у мужчин и -dóttir (исл. дочь) у женщин. Как правило, у исландцев нет фамилии, соответственно, отпадает вопрос о их использовании.
Вне зависимости от степени уважения обращающегося к объекту обращения исландцы называют его только по имени или же по имени и отчеству. Разумеется, назвать человека «г-жа Гвюдмюндсдоуттир» будет некорректным.
Супруги не изменяют чего-либо в своем имени, возможно заимствование фамилии в тех редких случаях, если она есть.
Сортировка по алфавиту осуществляется по имени, а не отчеству. Дабы прояснить повторяющиеся записи используются некоторые приемы, например, в телефонных книгах указываются профессии абонентов.
Схема «имя-отчество» также используется в южной Индии, Малайзии и Индонезии.
Малайское имя «Иса бин Осман» можно разбить на имя и отчество. Слово «бин» означает «сын (кого-либо)», у женщин используется «бинти». Для того, чтобы обратиться к этому человеку, подойдет «г-н Иса», «мистер Иса».
Различия в расположении составляющих
В китайском имени 毛泽东 («Мао Цзэдун») фамилией является «Мао», то есть первое при чтении слева направо. Личным именем является «Дун». Средний же слог «Цзэ» является именем поколения, и един для всех его братьев и сестер: 毛泽民 (Мао Цзэминь), 毛泽覃 (Мао Цзэтань), 毛泽紅 (Мао Цзэхун)
Китайская система имен является основой для всех традиционных способов именования людей в Восточной Азии.
Среди людей, которые не являются близкими к нему, к Мао могут обратиться как к 毛泽东先生 («Мао Цзэдун сяньшэн») или 毛先生 («Мао сяньшэн»), где «сяньшэн» - некий аналог «мистер» или «господин». Хотя на данный момент не у всех есть имя поколения, особенно в континентальном Китае, те, у кого оно есть, будут считать должным использование его вместе с личным именем. Поэтому, к человеку по имени 毛泽东 нельзя обратиться просто как 东, следует использовать 泽东.
В Японии, Корее и Венгрии фамилия также ставится вперед личного имени или личных имен.
Обратите внимание, что имена в записи иероглифами не разделяются пробелами. Существует множество различных систем транскрипции для различных азиатских языков, называемых по фамилиям их создателей. При этом транскрипция ужé транскрибированного слова из одного языка в другой, минуя изначальную форму, разумеется, приведет к ошибкам (сравните правильное «Такэси» и ерет. «Такеши»).
Китайцы, контактируя с представителями западной цивилизации, могут добавлять дополнительное личное имя, которое будет привычней для их новых друзей. К примеру, Яо Мин (фамилия - Яо, личное имя - Мин) может назваться иностранцам как Фред Яо Мин или Фред Мин Яо.

Множественные фамилии
Испанцы, как правило, имеют две фамилии. Например, дочь Antonio Campos Rodríguez (Антонио Кампос Родригес) и María Martínez Marqués (Марии Мартинес Маркес) зовут María Campos Martínez (Мария Кампос Мартинес). Обращаться к дочери следует Señorita Campos, а не Señorita Martínez.
При рождении португальский ребенок может получить одно или два имени и до четырех фамилий. Аналогичным образом дети получают фамилию от обоих родителей. У бразильцев также бывает до четырех фамилий, наследуемых от предков, например José Eduardo Santos Tavares Melo Silva.
Испанцы ставят фамилию отца перед фамилией матери, португальцы и бразильцы - наоборот, однако порядок может измениться. Также между именами могут появиться короткие слова, как то de или e между словами: Carreño de Quiñones, Tavares e Silva.
Меняющиеся формы слов
Отчество исландцев различается по полу его носителя. Однако, существуют и более сильные изменения. Русские и перенявшие русскую традицию имени вместе с русским языком народы стран бывшего СССР (Казахстан, Татарстан, Грузия и др.) используют отчество, употребляемое между фамилией и именем. Окончания отчества различаются по полу носителя. Сравните: Борис Николаевич Ельцин и Наина Иосифовна Ельцина - на конце имени мужа нет окончания, в то время как у жены добавляется «-а». Русские имена склоняются, при этом существуют несклоняемые, постоянные фамилии. Отличительной чертой русского именования является редкость матронимов.
Второе имя
Второе или среднее имя - традиция англоговорящих стран. Иногда под вторым понимают другие термины, например, двойные имена. В культуре Европы и западных стран обычно используется от одного до трех дополнительных имен. Второе имя представляет собой дополнительное личное имя и не является тождественным русскому отчеству, хотя и может быть дано в честь какого-либо родственника.
Американцы часто пишут собственное имя с инициалом посередине, например John Q. Public. Иногда форма, принятая в США, предлагается в виде общей традиции записи имен, даже в Соединенном Королевстве, где у людей может быть более одного второго имени. Британец сразу заметит подобные американские манеры. Корейцы, для которых типично иметь 3 имени, не записываемых в виде инициалов, удивятся «американской» форме ввода. Учтите также, что многие люди, использующие инициалы в их имени, могут предпочитать располагать их в начале имени.
Наследование имен
Члены одной семьи не всегда имеют одну и ту же фамилию. В современной западной цивилизации растет число жен, желающих сохранить собственные фамилии после вступления в брак, но в Китае подобная практика нормальна. В некоторых странах у жен есть выбор, брать или не брать имя мужа. Если малайка Зайтон выйдет замуж за Иса, она может остаться г-жой Зайтон, или же взять двойную фамилию «Зайтон Иса», которая предполагает обращение «г-жа Иса».
Испаноязычные фамилии также отличаются. В 1996-ом году Manuel A. Pérez Quiñones описал фамилии своей семьи или апеллидо: сам он стал Pérez Quiñones, потому как апеллидо его отца были Pérez Rodríguez, а апеллидо матери - Quiñones Alamo. Позже он встречался с девушкой с апеллидо Padilla Falto. После свадьбы её аппелидо стали Padilla de Pérez, а их дети имеют апеллидо Pérez Padilla. Суть в том, что лишь у родных братьев и сестер одни и те же апеллидо.
(Имя Manuel было незначительно изменено: на самом деле его апеллидо Pérez-Quiñones вместо варианта с пробелом, который был представлен для того, чтобы механизм образования имен был более понятным.)
Также нельзя просто полагаться на прием фамилии от мужа к жене, иногда женихи берут фамилии невест. В таком случае будет лучше говорить «девичья фамилия» или «бывшее имя» «урожденная(ый) (далее девичья фамилия)».
Смешение стилей
Многие культуры смешивают традиции имен, характерные для двух или более, а также добавляют собственные изобретения.
Например, «Velikkakathu Sankaran Achuthanandan» является кералским именем южной Индии, обычно записывается в виде «V. S. Achuthanandan» и представляет собой конструкцию «фамилия-отчество-имя».
Во многих частях света различные составляющие имени человека происходят от названий населенных пунктов, генеалогических особенностей, касты, религиозного статуса и т.д. Приведем несколько примеров:
Индийское имя «Когадду Бираппа Тимаппа Наир» следует рассматривать как комбинацию «название деревни - имя отца - личное имя - фамилия».
Раджастханское имя «Адитья Пратап Сингх Чаухан» состоит из личного имени, имени отца, фамилии и названия касты.
В другом регионе Индии имя «Мадурай Мани Айер» нужно толковать как набор «название города - личное имя - название касты».
Арабское «Абу Карим Мухаммед аль-Джамил ибн Нидал ибн Абдулазиз ал-Филистини» переводится как «Отец Карима, Мухаммед (личное имя), Красивый, Сын Нидала, Сын Абдулазиза, Палестинец», при этом Карим - первый сын Мухаммеда. Для дополнительной информации о подобной традиции богатых и длинных имен см. .
У жителей Таиланда есть прозвище, которым они называют друг друга в неофициальных ситуациях. Прозвище изначально никак не связано с настоящим именем. Поскольку прозвище состоит из одного-двух слогов, и его легче произносить, тайцы представляются иностранцам именно им. Например, прозвище бывшего премьер-министра Таксин Чиннават - Мау (แม้ว). Часто прозвища для семьи и друзей различаются.
Во Вьетнаме имя Nguyễn Tấn Dũng (Нгуен Тан Зунг) имеет смысл «фамилия - второе имя - личное имя». Хотя подобная система похожа на китайскую, есть небольшое отличие: даже в официальных ситуациях к премьер-министру Вьетнама нужно обращаться «г-н Зунг», а не «г-н Нгуен», то есть по имени.
Двусмысленность написания
Идеографическое письмо в японских именах создаёт проблемы: прочесть имя вслух можно более, чем одним способом. Это создаёт трудности как для людей, так и для систем алфавитной сортировки, потому как последняя осуществляется по прозношению. К примеру, фамилия 東海林賢蔵 (три первых идеограммы слева) может быть прочитана либо как «Токайрин», либо как «Содзи».
Более того, прозношение различных кандзи может совпадать, поэтому романизация и кириллизация неизбежно ведут к потерям смысла: все из фамилий 庄司, 庄子, 東海林 и 小路 читаютя как «Содзи».
В некоторых японских именах используются устаревшие и вышедшие из употребления идеограммы, прочитать которые будет затруднительно.
Из-за рассмотренных проблем японцы предпочитают снабжать собственное имя в обычном написании версией записи в неидеографическом слоговом алфавите кана.
Последствия для дизайна форм вввода
Как уже было упомянуто выше, возможным путем решения проблем является локализация для каждой конкретной культурноязыковой среды. Теоретически, это должно позволить приспособить интерфейс к каждой конкретной целевой аудитории. К сожалению, у такого подхода есть несколько недостатков:
- При необходимости централизации информации из нескольких видов ввода в единой базе данных возникнут затруднения в синтезировании схемы хранения.
- Кроме того, может возникнуть ситуация, когда упор на определение необходимой схемы именования по местоположению пользователя не сработает: возможны иностранцы, адаптирующиеся к чужой культурной среде, а также зарубежные элементы. Например, у сингапурцев бывают китайские, малайские и южноиндийские корни. Также вероятны более, чем одни использования имен. Поэтому ваш интерфейс должен оставаться гибким.
Разбить или не разбить?
При разработке дизайна формы ввода или базы данных, куда пользователи будут вводить личные данные, нужно сразу задаться вопросом, необходимо ли разделить личное имя и фамилию. Всё зависит от поставленных задач, но, как очевидно, наиболее простым будет просто оставить поле полного имени.

Учтите, что имена в некоторых культурах могут быть длинней, чем в вашей, поэтому поле ввода должно быть достаточно длинным, чтобы пользователь мог видеть его полностью по мере набора. Также не ограничивайте поля имени в базах данных. В частности, четырехсимвольное японское имя при кодировании UTF-8 в четыре байта не влезет, ему понадобится 12.
Пути деления имен на части
Если вам всё-таки предпочтительней хранить части имени раздельно, старайтесь избегать названий «Личное имя» и «Фамилия» в нелокализованных формах ввода, поскольку некоторым будет удобней писать фамилию, а следом за ними личные имена.

Для некоторых культур подобное будет не слишком приемлимо (например, для исландцев, не имеющих фамилии как таковой), но в целом это наиболее подходящее решение.
В случае, если вы хотите определить части имени для алфавитной сортировки, контактов и т.д. рассмотрите введение к существующему полю полного имени дополнительных, в которых пользователь может указать части имени, которые нужны для особых целей.
Иногда разделение имени на части выполняется с целью употребления одной из них в обращении: «I"m afraid I can"t do that, Dave.» Подобное может употребляться как в интерфейсе, так и в оповещениях по электронной почте. Разумеется, обращение, например, по имени в одних контекстах будет приветствоваться, человек же другой национальной культуры может воспринять его негативно и наоборот. Варьироваться отношение к окрику по имени может и в одной нации. В таком случае будет лучше в самом начале спросить у пользователя, как его называть.

Это дополнителное значение также будет полезно для определения прозвища тайцев.
Поскольку японские имена читаются по разному, для сортировки японских имен потребуется дополнительное поле, в которое они смогут ввести прозношение своего имени. Информация из этого поля и будет использоваться для сортировки японских имен.
Если вы разбиваете поля имен, убедитесь в том, что каждое поле ввода имеет ясную подпись. Не опирайтесь на то, что пользователь точно будет вводить фамилию после личного имени.
Будьте внимательны по отношению к допущениям алгоритмов, автоматически разбивающих полное имя на части. К примеру, оптимизация имен v-card или h-card может плохо работать с китайскими именами. Необходимо как можно точнее информировать пользователя, как указывать свои данные.
Существуют имена длиной в один символ. У людей с подобными короткими именами могут возникнуть проблемы с приложениями, отвергающими введенные данные как имя с инициалами. Если необходимо проследить за вводом инициалов, добавьте сообщение для пользователей, а не фильтруйте ввод.
Не делайте ввод фамилии обязательными: у населения Южной Индии, Малайзии, Индонезии и многих других стран есть только личное имя. Пользователям придется вводить какой-то мусор типа «Mr.», «.» в поля или, что гораздо хуже, не использовать ваш продукт вообще.
Другие замечания
Не забывайте разрешить пользователю использовать в именах знаки препинания: дефисы, апострофы и т.д. Пользователю может понадобиться ввести текст с пробелами, как то добавить префиксы и суффиксы: «де» у французов, «фон» у немцев, «Мл.» («Младший») у американцев; также последовательности букв, разделенные пробелом, могут являться корректными именами: «Роза Мария».
Члены одной семьи могут иметь разные фамилии. Не только женщины могут менять фамилии после вступления в брак, поэтому название поля ввода фамилии при рождении лучше выбрать без упора на пол: «Предыдущее имя», а не «Девичья фамилия».
Если вы разрабатываете формы ввода, которые будут локализованы в каждой конкретной культурной среде, не забудьте о том, что имя, разбитое на части, наверняка придется хранить в централизованной базе данных, которая потребует представить все запутанные части в доступном для хранения и извлечения виде.
Поддержка символов
Многие пользователи не используют латинский алфавит или используют наборы с множеством добавочных символов. Это представляется очевидным, но всё же чревато несколькими последствиями для дизайнеров, о которых часто забывают.
Если разрабатывается форма на английском, нужно решить, ожидается ли от пользователя ввод имени в национальных символах (например, 小林康宏), только в латинице (Yasuhiro Kobayashi) или же в обеих формах.
Помните, что даже английские имена могут содержать буквы, не содержащиеся в кодировке ASCII (например, Zoë).
С другой стороны бывают ситуации (необходимо задать логин, система поддерживает только ASCII), в которых разрешить национальные символы будет невозможно.
То, что пользователи укажут в форме ввода, чаще всего зависит от языка страницы. Если страница переведена на их родной язык, наиболее возможно получить имя, записанное не только латиницей.
В отношении букв, кодировка ASCII означает набор основных букв английского алфавита, то есть ABCDEFGHIJKLMNOPQRSTUVWXYZ и такой же состав строчных букв.
Если вам нужна только латиница, собщите об этом пользователю в интерфейсе формы ввода. Не забудьте проинструктировать и переводчиков.

Выбор формы ввода и хранения данных зависит от целей сбора информации и её использования.
- Вы собираетесь использовать имя человека как идентификатор в системе? В таком случае нет разницы, ASCII или национальное написание.
- Вы хотите обращаться к пользователю по имени на странице приветствия или в корреспонденции? В случае формирования переведенной на их родной язык страницы будет логичней использовать имя в их национальном написании.
- Важно ли для сотрудников вашей организации иметь возможность разбираться в записях и читать их имена? Тогда запросите латинскую транскрипцию.
- Будет ли их имя индексировано поисковыми системами? Или вы хотите обращаться к пользователям в рассылках по имени, но внутренние операции осуществлять на английском? Тогда в форме ввода запросите в раздельных полях как национальное написание, так и транскрипцию.

Обратите внимание на то, что японцам может понадобиться поле для транскрипции имени в японской слоговой азбуке, что потребует добавления третьего поля в примере выше.
При использовании символов вне набора ASCII не забудьте о кодировке страницы, приложения и базы данных.
На заметку
Пометка о сортировке
Имена людей не всегда сортируются по фамилии. Например, тайцы и исландцы используют сортировку по личному имени.
Также различаются методы сортировки и в испанидаде. María-Jose Carreño Quiñones из одного места будет искать себя как Carreño Quiñones, а её полная тёзка, проживающая в другом месте, где принята другая система сортировки, начнёт с Quiñones.
Небольшие слова «фон», «де», «ван» добавляют сложности. Иногда префиксы учитываются, иногда нет.
Формализм
Уровень формализма различается в разных странах, и это нужно учитывать при обращении к пользователю. В западной культурной среде принято обращаться по личному имени, но в Соединенном Королевстве обращение при первой встрече по личному имени покажет собеседнику, что вы с ним уже где-то виделись.
С другой стороны, использование обращения и личного имени («Mr. Richard») или лишь фамилии («Ishida!») приемлемо в некоторых частях света, но не во всех (например, в Британии).
В Германии титулы и звания важны, поэтому лучше обратиться не «Herr Schmidt», а «Herr Professor Doktor Schmidt».
В культурах, подобных японской, существуют именные суффиксы, выражающие почтение, должность или звание. Лучше обратиться к кому-то как «Tanaka-san» или «Tanaka-sama» (зависит от степени уважения). Руководитель отдела по имени Tanaka ожидает от вас обращения Tanaka-bucho (букв. «руководитель отдела Танака»). Хотя можно добавить -san к личным именам, в рабочей среде подобное обращение будет выглядеть странно.
Дополнительная информация
Информация выше предоставляет лишь краткую справку о трудностях, с которыми может столкнуться разработчик. В реальности даже в сфере одной культуры ситуация может оказаться ещё более запутанной и усложненной. Англоязычная «Википедия» предоставляет множество подробных статей, рассказывающих о формировании имен людей в различных частях света. Рекомендуется прочитать и понять данные статьи.
§ 1.6. Система управления базами данных
Вопросы и задания к § 1.6. Система управления базами данных
1. Ознакомьтесь с материалами презентации к параграфу, содержащейся в электронном приложении к учебнику. Используйте эти материалы при подготовке ответов на вопросы и выполнении заданий.
2. Что такое СУБД?
3. Какая СУБД установлена на компьютерах в вашем классе?
4. С чего начинается создание БД?
5. Перечислите основные объекты СУБД. Какие функции они выполняют?
6. Ниже в табличной форме представлены характеристики ноутбуков, имеющихся в продаже в компьютерном салоне:

а) Какую строку будет занимать запись, содержащая сведения о ноутбуке Asus F70SL, после сортировки данных по возрастанию значений поля НАЗВАНИЕ?
б) Какую строку будет занимать запись, содержащая сведения о ноутбуке Asus F70SL, после сортировки данных по убыванию значений поля ЖЁСТКИЙ ДИСК?
в) Какую строку будет занимать запись, содержащая сведения о ноутбуке Asus F70SL, после сортировки данных сначала по убыванию значений поля ОПЕРАТИВНАЯ ПАМЯТЬ, затем по возрастанию значений поля ЖЁСТКИЙ ДИСК?
7. Как будет выглядеть список (фамилия, имя) учеников после сортировки данных по возрастанию значений поля ДАТА РОЖДЕНИЯ базы данных «Наш класс» (рис. 1.18)?
8. Укажите все записи базы данных «Наш класс» (рис. 1.18), для которых будут истинными простые логические выражения 1-6 (табл. 1.6).
9. Укажите все записи базы данных «Наш класс» (рис. 1.18), для которых будут истинными сложные логические выражения 1-3 (табл. 1.7).
10. Какова цель запроса на выборку?
11. Ниже в табличной форме представлен фрагмент базы данных с годовыми оценками учащихся:

а) АЛГЕБРА>3 И ИНФОРМАТИКА>4 И ПОЛ="М"
б) (АЛГЕБРА>4 ИЛИ ИНФОРМАТИКА>4) И ПОЛ="Ж"
в) ФИЗИКА=3 ИЛИ АЛГЕБРА=3 ИЛИ ГЕОМЕТРИЯ=3 ИЛИ ИНФОРМАТИКА=3
г) (ФИЗИКА=3 ИЛИ АЛГЕБРА=3) И (ГЕОМЕТРИЯ=3 ИЛИ ИНФОРМАТИКА=3)
12. Ниже в табличной форме представлен фрагмент базы данных с результатами олимпиады по информатике:

Сколько записей в данном фрагменте удовлетворяет следующему условию?
а) ПОЛ="М" И СУММА>55
б) (ЗАДАЧА<ЗАДАЧА2) И (ЗАДАЧА2<ЗАДАЧА3)
в) ЗАДАЧА 1=30 ИЛИ ЗАДАЧА2=30 ИЛИ ЗАДАЧА3=30
г) ЗАДАЧА 1=30 И ЗАДАЧА2=30 И ЗАДАЧА3=30